I clearly nerdsniped Terence at least a little when I asked whether a blog necessarily had to be HTML, because he went on to implement a WordPress theme that delivers content entirely in plain text.
theunderground.blog‘s content, with the exception of its homepage, is delivered entirely through an XML Atom feed. Atom feed entries do require <title>s, of course, so that’s not the strongest counterexample!
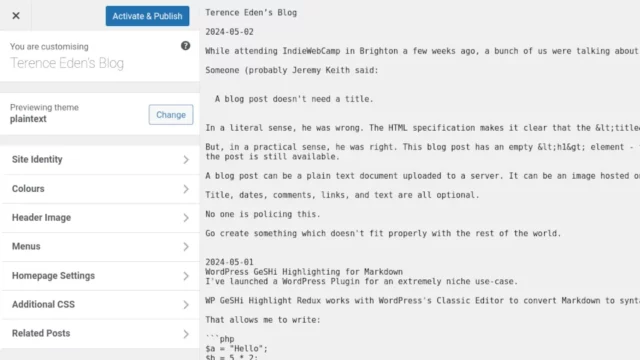
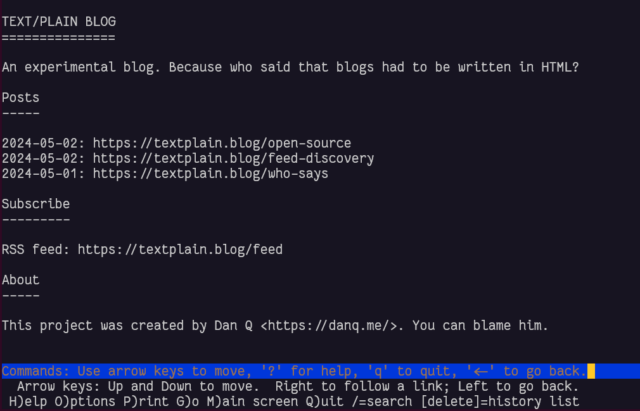
This blog is available over several media other than the Web. For example, you can read this blog post:
We’ve looked at plain text, which as a format clearly does not have to have a title. Let’s go one step further and implement it. What we’d need is:
A webserver configured to deliver plain text files by preference, e.g. by adding directives like index index.txt; (for Nginx).5
An index page listing posts by date and URL. Most browser won’t render these as “links” so users will have to copy-paste
or re-type them, so let’s keep them short,
Pages for each post at those URLs, presumably without any kind of “title” (just to prove a point), and
An RSS feed: usually I use RSS as shorthand for all feed
types, but this time I really do mean RSS and not e.g. Atom because RSS, strangely, doesn’t require that an <item> has a <title>!
Unlike other sites, I didn’t need to test textplain.blog in Lynx to
know it’d work well. But I did anyway.
In the end I decided it’d benefit from being automated as sort-of a basic flat-file CMS, so I wrote it in PHP. All requests are routed by the webserver to the program, which determines whether they’re a request for the homepage, the RSS feed, or a valid individual post, and responds accordingly.
It annoys me that feed
discovery doesn’t work nicely when using a Link: header, at least not in any reader I tried. But apart from that, it seems pretty solid, despite its limitations. Is this,
perhaps, an argument for my.well-known/feedsproposal?
When was the last time you tested your website in a text-only browser like Lynx (or ELinks, or one of
several others)? Perhaps you
should.
I’m a big fan of CSS Naked Day. I love the idea of JS Naked Day, although I missed it earlier this month (I was busy abroad, plus my aggressive caching,
including in service workers, makes it hard to reliably make sweeping changes for short periods). I’m a big fan of the idea that, for the vast majority of websites, if it isn’t at least
usable without any CSS or JavaScript, it should probably be considered broken.
This year, I thought I’d celebrate the events by testing DanQ.me in the most-limited browser I had to-hand: Lynx. Lynx has zero CSS or JavaScript support, along with limited-to-no support for heading levels, tables, images, etc. That may seem extreme, but it’s a reasonable
analogue for the level of functionality you might routinely expect to see in the toughest environments in which your site is accessed: slow 2G connections from old mobile hardware,
people on the other side of highly-restrictive firewalls or overenthusiastic privacy and security software, and of course users of accessibility technologies.
Here’s what broke (and some other observations):
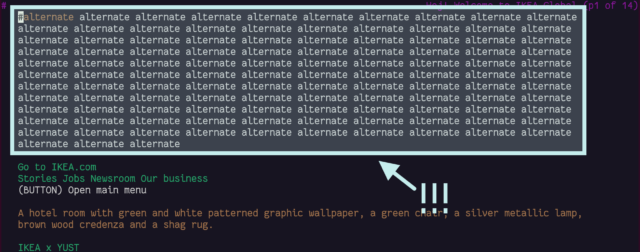
<link rel="alternate">s at the top
I see the thinking that Lynx (and in an even more-extreme fashion, ELinks) have with showing “alternate versions” of a page at the top, but it’s not terribly helpful: most of mine are
designed to help robots, not humans!
Four alternates is pretty common for a WordPress site: post feed, comments feed, and two formats of oEmbed.
I wonder if switching from <link rel="alternate"> elements to Link: HTTP headers would
indicate to Lynx that it shouldn’t be putting these URLs in humans’ faces, while still making them accessible to all the
services that expect to find them? Doing so would require some changes to my caching logic, but might result in a cleaner, more human-readable HTML file as a side-effect. Possibly something worth investigating.
Fortunately, I ensure that my <link rel="alternate">s have a title attribute, which is respected by Lynx and ELinks and makes these scroll-past links
slightly less-confusing.
Not all sites title their alternate links. IKEA.com requires you to scroll through 113 anonymous links for their alternate language versions, because Lynx doesn’t understand the
hreflang attribute.
Post list indentation
Posts on the homepage are structured a little like this:
Strictly-speaking, that’s not valid. Heading elements are only permitted within flow elements. I chose to implement it that way because it seemed to be the most semantically-correct way
to describe the literal “list of posts”. But probably my use of <h2> is not the best solution. Let’s see how Lynx handles it:
Lynx “outdents” headings so they stand out, and “indents” lists so they look like lists. This causes a quirky clash where a heading is inside a list.
It’s not intolerable, but it’s a little ugly.
CSS lightboxes add a step to images
I use a zero-JavaScript approach to image lightboxes: you can see it by clicking
on any of the images in this post! It works by creating a (closed) <dialog> at the bottom of the page, for each image. Each <dialog> has a unique
id, and the inline image links to that anchor.
Originally, I used a CSS :target selector to detect when the link had been clicked and show the
<dialog>. I’ve since changed this to a :has(:target) and directed the link to an element within the dialog, because it works better on browsers
without CSS support.
It’s not perfect: in Lynx navigating on an inline image scrolls down to a list of images at the bottom of the page and selects the current one: hitting the link again now
offers to download the image. I wonder if I might be better to use a JavaScript-powered lightbox after all!
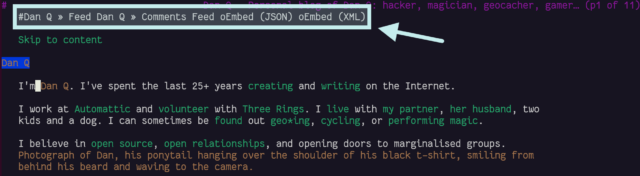
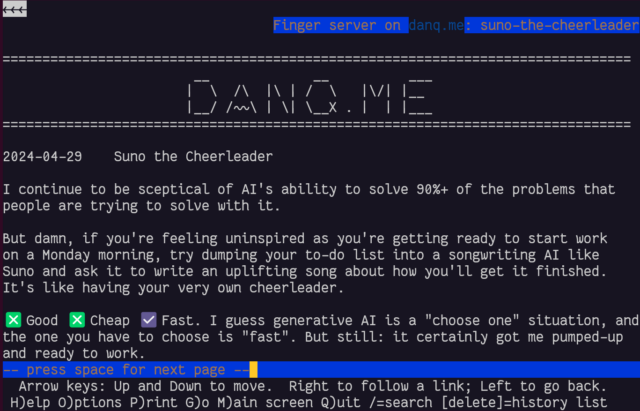
gopher: and finger: links work perfectly!
I was pleased to discover that gopher: and finger: links to alternate copies of a post… worked perfectly! That shouldn’t be a surprise – Lynx natively supports
these protocols.
In a fun quirk and unusually for a standard of its age, the Finger specification did not state the character encoding that ought to
be used. I guess the authors just assumed everybody reading it would use ASCII. But both my
WordPress-to-Finger bridge and Lynx instead assume that UTF-8 is acceptable (being a superset of
ASCII, that seems fair!) which means that emoji work (as shown in the screenshot above). That’s
nuts, isn’t it?
You can’t react to anything
Back in November I added the ability to “react” to a post by clicking an emoji, rather than
typing out a full comment. Because I was feeling lazy, the feature was (and remains) experimental, and I didn’t consider it essential functionality, I implemented it mostly in
JavaScript. Without JavaScript, all you can do is see what others have clicked.
The available emoji vary from post to post; I sometimes like to throw a weird/fun one in there, knowing that it’ll invariably be Ruth that
clicks it first.
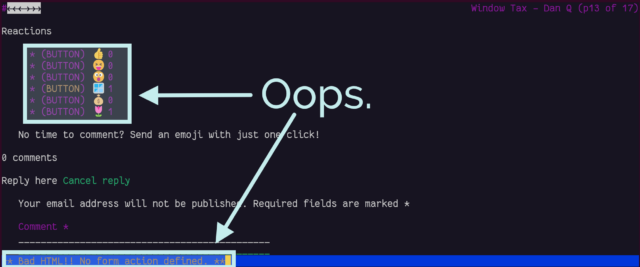
In a browser with no JavaScript but with functional CSS, the buttons correctly appear disabled.
But with neither technology available, as in Lynx, they look like they should work, but just… don’t. Oops.
Lynx is correct; this is sloppy code. Without CSS support, it even shows the instruction that implies the buttons will work, but they don’t.
If I decide to keep the reaction buttons long-term, I’ll probably reimplement them so that they function using plain-old HTML
and HTTP, using a <form>, and refactor my JavaScript to properly progressively-enhance the buttons for
those that support it. For now, this’ll do.
Comment form honeypot
The comment form on my blog posts works… but there’s a quirk:
At the end of the comments form, an additional <textarea> appears!
That’s an annoyance. It turns out it’s a honeypot added by Akismet: a fake comments field, normally hidden, that tries to trick spam bots into filling
it (and thus giving themselves away): sort-of a “reverse CAPTCHA” where the
robots do something extra, unintentionally, to prove their inhumanity. Lynx doesn’t understand the code that Akismet uses to hide the form, and so it’s visible to humans, which
is suboptimal both because it’s confusing but also because a human who puts details into it is more-likely to be branded a spambot!
I might look into suppressing Akismet adding its honeypot field in the first place, or else consider one of the alternative anti-spam plugins for WordPress. I’ve heard good things about
Antispam Bee; I ought to try it at some point.
Overall, it’s pretty good
On the whole, DanQ.me works reasonably well in browsers without any JavaScript or CSS capability, with only a few optional
features failing to function fully. There’s always room for improvement, of course, and I’ve got a few things now to add to my “one day” to-do list for my little digital garden.
Obviously, this isn’t really about supporting people using text-mode browsers, who probably represent an incredible minority. It’s about making a real commitment to the
semantic web, to accessibility, and to progressive enhancement! That making your site resilient, performant, and accessible also helps make it function in even the
most-uncommon of browsers is just a bonus.
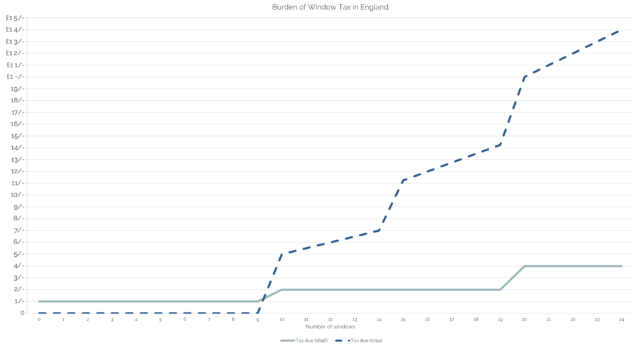
From 1696 until 1851 a “window tax” was imposed in England and Wales1.
Sort-of a precursor to property taxes like council tax today, it used an estimate of the value of a property as an indicator of the wealth of its occupants: counting the number of
windows provided the mechanism for assessment.
The hardest thing about retrospectively graphing the cost of window tax is thinking in “old money”2.
Window tax replaced an earlier hearth tax, following the ascension to the English throne of Mary II and William III of Orange. Hearth tax had come from a similar philosophy: that
you can approximate the wealth of a household by some aspect of their home, in this case the number of stoves and fireplaces they had.
(A particular problem with window tax as enacted is that its “stepping”, which was designed to weigh particularly heavily on the rich with their large houses, was that it similarly
weighed heavily on large multi-tenant buildings, whose landlord would pass on those disproportionate costs to their tenants!)
It’d be temping to blame William and Mary for the window tax, but the reality is more-complex and reflects late renaissance British attitudes to the limits of state authority.
Why a window tax? There’s two ways to answer that:
A window tax – and a hearth tax, for that matter – can be assessed without the necessity of the taxpayer to disclose their income. Income tax, nowadays the most-significant form of
taxation in the UK, was long considered to be too much of an invasion upon personal privacy3.
But compared to a hearth tax, it can be validated from outside the property. Counting people in a property in an era before solid recordkeeping is hard. Counting hearths is
easier… so long as you can get inside the property. Counting windows is easier still and can be done completely from the outside!
If you’re in Britain, finding older buildings with windows bricked-up to save on tax is pretty easy. I took a break from writing this post, walked for three minutes, and found
one.4
There were a few work-related/adjacent activities. But also a table football tournament, among other bits of fun.
One of the things I learned while on this trip was that the Netherlands, too, had a window tax for a time. But there’s an interesting difference.
The Dutch window tax was introduced during the French occupation, under Napoleon, in 1810 – already much later than its equivalent in England – and continued even after he was ousted
and well into the late 19th century. And that leads to a really interesting social side-effect.
My brief interest in 19th century Dutch tax policy was piqued during my team’s boat tour.
Glass manufacturing technique evolved rapidly during the 19th century. At the start of the century, when England’s window tax law was in full swing, glass panes were typically made
using the crown glass process: a bauble of glass would be
spun until centrifugal force stretched it out into a wide disk, getting thinner towards its edge.
The very edge pieces of crown glass were cut into triangles for use in leaded glass, with any useless offcuts recycled; the next-innermost pieces were the thinnest and clearest, and
fetched the highest price for use as windows. By the time you reached the centre you had a thick, often-swirly piece of glass that couldn’t be sold for a high price: you still sometimes
find this kind among the leaded glass in particularly old pub windows5.
They’re getting rarer, but I’ve lived in houses with small original panes of crown glass like these!
As the 19th century wore on, cylinder glass became the norm. This is produced by making an iron cylinder as a mould, blowing glass into it, and then carefully un-rolling the cylinder
while the glass is still viscous to form a reasonably-even and flat sheet. Compared to spun glass, this approach makes it possible to make larger window panes. Also: it scales
more-easily to industrialisation, reducing the cost of glass.
The Dutch window tax survived into the era of large plate glass, and this lead to an interesting phenomenon: rather than have lots of windows, which would be expensive,
late-19th century buildings were constructed with windows that were as large as possible to maximise the ratio of the amount of light they let in to the amount of tax for which
they were liable6.
Look at the size of those windows! If you’re limited in how many you can have, but you’ve got the technology, you’re going to make them as large as you possibly can!
That’s an architectural trend you can still see in Amsterdam (and elsewhere in Holland) today. Even where buildings are renovated or newly-constructed, they tend – or are required by
preservation orders – to mirror the buildings they neighbour, which influences architectural decisions.
Notice how each building has only between one and three windows on the ground floor, letting as much light in while minimising the tax burden.
It’s really interesting to see the different architectural choices produced in two different cities as a side-effect of fundamentally the same economic choice, resulting from slightly
different starting conditions in each (a half-century gap and a land shortage in one). While Britain got fewer windows, the Netherlands got bigger windows, and you can still see the
effects today.
…and social status
But there’s another interesting this about this relatively-recent window tax, and that’s about how people broadcast their social status.
This Google Street Canal (?) View photo shows a house on Keizersgracht, one of the richest parts of Amsterdam. Note the superfluous decorative window above the front door
and the basement-level windows for the servants’ quarters.
In some of the traditionally-wealthiest parts of Amsterdam, you’ll find houses with more windows than you’d expect. In the photo above, notice:
How the window density of the central white building is about twice that of the similar-width building on the left,
That a mostly-decorative window has been installed above the front door, adorned with a decorative
leaded glass pattern, and
At the bottom of the building, below the front door (up the stairs), that a full set of windows has been provided even for the below-ground servants quarters!
When it was first constructed, this building may have been considered especially ostentatious. Its original owners deliberately requested that it be built in a way that would attract a
higher tax bill than would generally have been considered necessary in the city, at the time. The house stood out as a status symbol, like shiny jewellery, fashionable clothes,
or a classy car might today.
I originally wanted to insert a picture here that represented how one might show status through fashion today. But then I remembered I don’t know anything about fashion7. But somehow my stock image search suggested this photo, and I
love it so much I’m using it anyway. You’re welcome.
How did we go wrong? A century and a bit ago the super-wealthy used to demonstrate their status by showing off how much tax they can pay. Nowadays, they generally seem
more-preoccupied with getting away with paying as little as possible, or none8.
Can we bring back 19th-century Dutch social status telegraphing, please?9
Footnotes
1 Following the Treaty of Union the window tax was also applied in Scotland, but
Scotland’s a whole other legal beast that I’m going to quietly ignore for now because it doesn’t really have any bearing on this story.
2 The second-hardest thing about retrospectively graphing the cost of window tax is
finding a reliable source for the rates. I used an archived copy of a guru site about Wolverhampton history.
3 Even relatively-recently, the argument that income tax might be repealed as incompatible
with British values shows up in political debate. Towards the end of the 19th century, Prime Ministers Disraeli and Gladstone could be relied upon to agree with one another on almost
nothing, but both men spoke at length about their desire to abolish income tax, even setting out plans to phase it out… before having to cancel those plans when some
financial emergency showed up. Turns out it’s hard to get rid of.
4 There are, of course, other potential reasons for bricked-up windows – even aesthetic ones – but a bit of a giveaway is if the bricking-up
reduces the number of original windows to 6, 9, 14 or 19, which are thesholds at which the savings gained by bricking-up are the greatest.
5 You’ve probably heard about how glass remains partially-liquid forever and how this
explains why old windows are often thicker at the bottom. You’ve probably also already had it explained to you that this is complete bullshit. I only
mention it here to preempt any discussion in the comments.
6 This is even more-pronounced in cities like Amsterdam where a width/frontage tax forced
buildings to be as tall and narrow and as close to their neighbours as possible, further limiting opportunities for access to natural light.
7 Yet I’m willing to learn a surprising amount about Dutch tax law of the 19th century. Go
figure.
I’ve got a (now four-year-old) Unraid NAS called Fox and I’m a huge fan. I particularly love the fact that Unraid can work not only as a NAS, but also as a fully-fledged Docker appliance, enabling me to easily install and maintain all manner of applications.
There isn’t really a generator attached to Fox, just a UPS battery backup. The sign was liberated from our shonky home electrical system.
I was chatting this week to a colleague who was considering getting a similar setup, and he seemed to be taking notes of things he might like to install, once he’s got one. So I figured
I’d round up five of my favourite things to install on an Unraid NAS that:
Don’t require any third-party accounts (low dependencies),
Don’t need any kind of high-powered hardware (low specs), and
Provide value with very little set up (low learning curve).
It’d have been cooler if I’d have secretly written this blog post while sitting alongside said colleague (shh!). But sadly it had to wait until I was home.
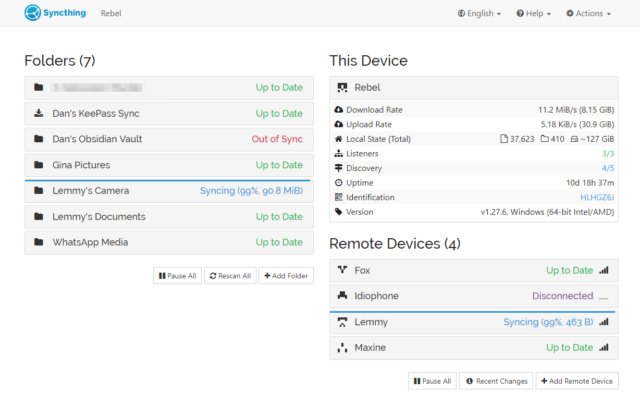
Syncthing’s just an awesome piece of set-and-forget software that facilitates file synchronisation between all of your devices and can also form part of a backup strategy.
Here’s the skinny: you install Syncthing on several devices, then give each the identification key of another to pair them. Now you can add folders on each and “share” them with the
others, and the two are kept in-sync. There’s lots of options for power users, but just as a starting point you can use this to:
Manage the photos on your phone and push copies to your desktop whenever you’re home (like your favourite cloud photo sync service, but selfhosted).
Keep your Obsidian notes in-sync between all your devices (normally costs $4/month).1
Get a copy of the documents from all your devices onto your NAS, for backup purposes (note that sync’ing alone, even with
versioning enabled, is not a good backup: the idea is that you run an actual backup from your NAS!).
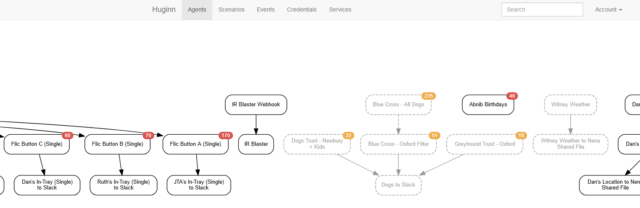
You know IFTTT? Zapier? Services that help you to “automate” things based on inputs and outputs. Huginn’s like that, but selfhosted.
Also: more-powerful.
When we first started looking for a dog to adopt (y’know, before we got this derper), I set up Huginn watchers to monitor the websites of several rescue centres, filter them by some of our criteria, and push
the results to us in real-time on Slack, giving us an edge over other prospective puppy-parents.
The learning curve is steeper than anything else on this list, and I almost didn’t include it for that reason alone. But once you’ve learned your way around its idiosyncrasies and
dipped your toe into the more-advanced Javascript-powered magic it can do, you really begin to unlock its potential.
It couples well with Home Assistant, if that’s your jam. But even without it, you can find yourself automating things you never expected to.
Many of these suggested apps benefit well from you exposing them to the open Web rather than just running them on your LAN,
and an RSS reader is probably the best example (you want to read your news feeds when you’re out and about, right?). What you
need for that is a reverse proxy, and there are lots of guides to doing it super-easily, even if you’re not on a static IP
address.2.
Alternatively you can just VPN in to your home: your router might be able to arrange this, or else Unraid can do it for you!
You know how sometimes you need to give somebody your email address but you don’t actually want to. Like: sure, I’d like you to email me a verification code for this download, but I
don’t trust you not to spam me later! What you need is a disposable email address.3
How do you feel about having infinite email addresses that you can make up on-demand (without even having access to a computer), subscribe to by RSS, and never have to see unless you specifically want to.
You just need to install Open Trashmail, point the MX records of a few domain names or subdomains (you’ve got some spare domain names
lying around, right? if not; they’re pretty cheap…) at it, and it will now accept email to any address on those domains. You can make up addresses off the top of your head,
even away from an Internet connection when using a paper-based form, and they work. You can check them later if you want to… or ignore them forever.
Couple it with an RSS reader, or Huginn, or Slack, and you can get a notification or take some action when an email arrives!
Need to give that escape room your email address to get a copy of your “team photo”? Give them a throwaway, pick up the picture when you get home, and then forget you ever gave it
to them.
Company give you a freebie on your birthday if you sign up their mailing list? Sign up 366 times with them and write a Huginn workflow that puts “today’s” promo code into your
Obsidian notetaking app (Sync’d over Syncthing) but filters out everything else.
Suspect some organisation is selling your email address on to third parties? Give them a unique email address that you only give to them and catch them in a honeypot.
It isn’t pretty, but… it doesn’t need to be! Nobody actually sees the admin interface except you anyway.
Plus, it’s just kinda cool to be able to brand your shortlinks with your own name, right? If you follow only one link from this post, let it be to watch this video
that helps explain why this is important: danq.link/url-shortener-highlights.
I run many, many other Docker containers and virtual machines on my NAS. These five aren’t even the “top five” that I
use… they’re just five that are great starters because they’re easy and pack a lot of joy into their learning curve.
And if your NAS can’t do all the above… consider Unraid for your next NAS!
Footnotes
1 I wrote the beginnings of this post on my phone while in the Channel Tunnel and then
carried on using my desktop computer once I was home. Sync is magic.
2 I can’t share or recommend one reverse proxy guide in particular because I set my own up
because I can configure Nginx in my sleep, but I did a quick search and found several that all look good so I imagine you can do the same. You don’t have to do it on day one, though!
Like much of the UK, there are local elections where I live next month. After coming home from a week of Three Rings volunteering I found my poll card on the doormat. Can you spot the bleeding-obvious mistake?
Also interesting was that this year the poll card came in a tamper-evidence tear-to-open envelope rather than just being a piece of card. Does the government now think that postal
workers are routinely stealing voter identities? Cohabitees?
This’ll be the first election for which I’ve needed to bring photographic ID to the polling station. That shouldn’t be a problem: I have a passport and driving license and whatnot.
But just to be absolutely certain, I had the local council – the same people who issued me the polling card! – supply me with a voter authority certificate:
Note that this document, also issued by West Oxfordshire District Council, spells my name correctly.
So now I’m in a pickle. West Oxfordshire District Council are asking me to produce photo ID in the wrong name when I turn up at a polling station next month. It doesn’t even
match the name on the photo ID that they themselves issued me.
This would be less-infuriating were it not for the fact that they had my name wrong in the same way on an electoral roll form they sent me in August 20221.
When I contacted them to have them fix it, they promised that the underlying problem was solved2
so this very thing wouldn’t happen.
And yet here we are.
Hopefully they’ll be able to fix their records promptly or else I guess I’ll have to apply for a proxy vote, to allow the ballot of my imaginary friend “Dan Que” to be cast by me, Dan
Q, instead.
And if that isn’t the most bizarre form of election fraud you’ve ever heard of, I don’t know what is.
Update: True to their word, the council had managed to
correct their records by the time I reached the polling station this morning. It’s still a little annoying that they somehow mucked it up in the first place, but I appreciate the
efficiency with which they corrected their mistake.
Footnotes
1 They’d had my name right before August 2022, including on previous poll cards;
I can only assume that some human operator “corrected” it to the wrong thing at some point.
2 They didn’t fix the problem immediately in August 2022. Initially, they
demanded that I produce proof of my change of name from “Dan Que” (which has, of course, never been my name!) to “Dan Q”, and only later backed down and admitted that they’d
made a mistake and would correct the PII they were holding about me.
Anyway, here’s the best printer for 2024: a Brother laser printer. You can just pick any one you like; I have one with a sheet feeder and one without a sheet feeder. Both of them have
reliably printed return labels and random forms and pictures for my kid to color for years now, and I have never purchased replacement toner for either one. Neither has fallen off the
WiFi or insisted I sign up for an ink-related hostage situation or required me to consider the ongoing schemes of HP executives who seem determined to make people hate a legendary
brand with straightforward cash grabs and weird DRM ideas.
…
It’s sort-of alarming that Brother are the only big player in the printer space who subscribe to a philosophy of “don’t treat the customers like
livestock”. Presumably all it’d take is a board-level decision to flip the switch from “not evil” to “evil” and we’d lose something valuable. Thankfully, for now at least, they still
clearly see the value of the positive marketing the world gives them. Positive marketing like like this article.
The article is excellent, by the way. I know that I’m “supposed” to stir up hatred about the fact that its conclusion is written by an AI but… well, just read it for yourself and you’ll see why I don’t mind even one bit. Top notch reporting. Consider following the links within it to
stories about how other printer manufacturers continue to show exactly how shitty they can be.
I recommended a Brother printer to the Vagina Museum the other month. I assume it ‘s still working out fine for them (and not ripping them off, spying on them, and/or contributing to the
destruction of the the planet).
I was contacted this week by a geocacher called Dominik who, like me, loves geocaching…. but hates it when the coordinates for a cache are hidden behind a virtual jigsaw puzzle.
A popular online jigsaw tool used by lazy geocache owners is Jigidi: I’ve come up with severaltechniques for bypassing their puzzles or at least making
them easier.
Not just any puzzle; the geocache used an ~1000 piece puzzle! Ugh!
I experimented with a few ways to work-around the jigsaw, e.g. dramatically increasing the “snap range” so dragging a piece any distance would result in it jumping to a
neighbour, and extracting original image URLs from localStorage. All were good, but none were
perfect.
For a while, making pieces “snap” at any range seemed to be the best hacky workaround.
Then I realised that – unlike Jigidi, where there can be a congratulatory “completion message” (with e.g. geocache coordinates in) – in JigsawExplorer the prize is seeing the
completed jigsaw.
You can click a button to see the “box” of a jigsaw, but this can be disabled by the image uploader.
Let’s work on attacking that bit of functionality. After all: if we can bypass the “added challenge” we’ll be able to see the finished jigsaw and, therefore, the geocache
coordinates. Like this:
Hackaround
Here’s how it’s done. Or keep reading if you just want to follow the instructions!
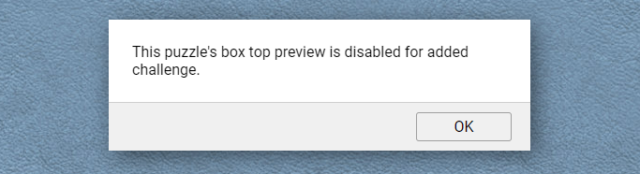
Open a jigsaw and try the “box cover” button at the top. If you get the message “This puzzle’s box top preview is disabled for added challenge.”, carry on.
Open your browser’s debug tools (F12) and navigate to the Sources tab.
Find the jigex-prog.js file. Right-click and select Override Content (or Add Script Override).
In the overridden version of the file, search for the string – e&&e.customMystery?tt.msgbox("This puzzle's box top preview is disabled for added challenge."): –
this code checks if the puzzle has the “custom mystery” setting switched on and if so shows the message, otherwise (after the :) shows the box cover.
Carefully delete that entire string. It’ll probably appear twice.
Reload the page. Now the “box cover” button will work.
The moral, as always, might be: don’t put functionality into the client-side JavaScript if you don’t want the user to be able to bypass it.
Or maybe the moral is: if you’re going to make a puzzle geocache, put some work in and do something clever, original, and ideally with fieldwork rather than yet another low-effort
“upload a picture and choose the highest number of jigsaw pieces to cut it into from the dropdown”.
Ever wondered why Oxford’s area code is 01865? The story is more-complicated than you’d think.
As a child, I was told that city STD codes were usually associated to the letters that appear on some telephones… but that
wouldn’t make any sense for Oxford’s code!
I’ll share the story on my blog, of course. But before then, I’ll be telling it from the stage of the Jericho Tavern at 21:15 on Wednesday 17 April as
my third(?) appearance at Oxford Geek Nights! So if you’re interested in learning about some of the quirks of UK telephone numbering
history, I can guarantee that this party’s the only one to be at that Wednesday night!
Not your jam? That’s okay: there’s plenty of more-talented people than I who’ll be speaking, about subjects as diverse as quantum computing with QATboxen, bringing your D&D experience to stakeholder management (!), video games
without screens, learnings from the Horizon scandal, and whatever Freyja Domville means by The Unreasonable Effectiveness of the Scientific Method (but I’m seriously excited by that title).
Anyway: I hope you’ll be coming along to Oxford Geek Nights 57 next month, if not to hear me witter on about the
fossils in our telecommunications networks then to enjoy a beer and hear from the amazing speakers I’ll be sharing the stage with. The event’s always a blast, and I’m looking forward to
seeing you there!
I used to have a single minor niggle with the BBC News RSS feed: that it included sports news, which I didn’t care
about. So I wrote a script that downloaded it, stripped
sports news, and re-exported the feed for me to subscribe to. Magic.
Lately my BBC News feed has caused me some annoyance and frustration.
But lately – presumably as a result of technical changes at the Beeb’s side – this feed has found two fresh ways to annoy me:
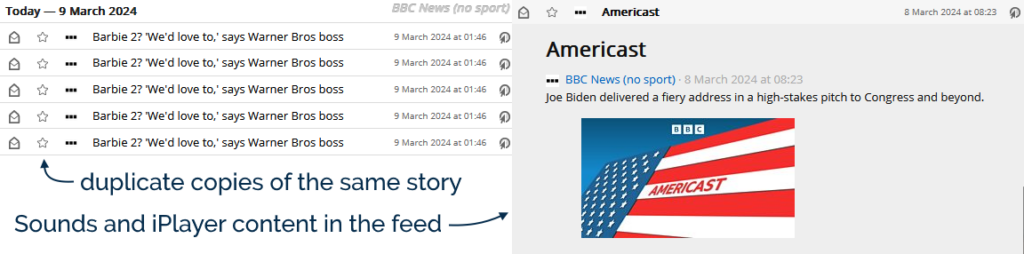
The feed now re-publishes a story if it gets re-promoted to the front page… but with a different<guid> (it appears to get a #0 after it
when first published, a #1 the second time, and so on). In a typical day the feed reader might scoop up new stories about once an hour, any by the time I get to reading them the
same exact story might appear in my reader multiple times. Ugh.
They’ve started adding iPlayer and BBC Sounds content to the BBC News feed. I don’t follow BBC News in my feed reader because I want to watch or listen to things. If
you do, that’s fine, but I don’t, and I’d rather filter this content out.
Luckily, I already have a recipe for improving this feed, thanks to my prior work. Let’s look at my newly-revised script (also available on GitHub):
#!/usr/bin/env rubyrequire'bundler/inline'# # Sample crontab:# # At 41 minutes past each hour, run the script and log the results# */20 * * * * ~/bbc-news-rss-filter-sport-out.rb > ~/bbc-news-rss-filter-sport-out.log 2>>&1# Dependencies:# * open-uri - load remote URL content easily# * nokogiri - parse/filter XML
gemfile do
source 'https://rubygems.org'
gem 'nokogiri'endrequire'open-uri'# Regular expression describing the GUIDs to reject from the resulting RSS feed# We want to drop everything from the "sport" section of the website, also any iPlayer/Sounds linksREJECT_GUIDS_MATCHING=/^https:\/\/www\.bbc\.co\.uk\/(sport|iplayer|sounds)\//# Load and filter the original RSS
rss =Nokogiri::XML(open('https://feeds.bbci.co.uk/news/rss.xml?edition=uk'))
rss.css('item').select{|item| item.css('guid').text =~REJECT_GUIDS_MATCHING }.each(&:unlink)
# Strip the anchors off the <guid>s: BBC News "republishes" stories by using guids with #0, #1, #2 etc, which results in duplicates in feed readers
rss.css('guid').each{|g|g.content=g.content.gsub(/#.*$/,'')}
File.open( '/www/bbc-news-no-sport.xml', 'w' ){ |f| f.puts(rss.to_s) }
It’s amazing what you can do with Nokogiri and a half dozen lines of Ruby.
That revised script removes from the feed anything whose <guid> suggests it’s sports news or from BBC Sounds or iPlayer, and also strips any “anchor” part of the
<guid> before re-exporting the feed. Much better. (Strictly speaking, this can result in a technically-invalid feed by introducing duplicates, but your feed reader
oughta be smart enough to compensate for and ignore that: mine certainly is!)
You’re free to take and adapt the script to your own needs, or – if you don’t mind being tied to my opinions about what should be in BBC News’ RSS feed – just subscribe to my copy at: https://fox.q-t-a.uk/bbc-news-no-sport.xml
A devastating blow by RSS against a competitor 19 years his junior! For updates on this bout as it develops, don’t forget to subscribe… using either protocol.
When I subscribe to content, I want:
Resilient failsafes. ActivityPub has many points-of-failure. A notification might fail to complete transmission as a result of downtime, faults, or network
conditions, and the receiving server might never know. A feed reader, conversely, can tell you that an address 404’d or the server was down.
Retroactive access. Once you fix the problem above… you still don’t get the message you missed: it’s probably gone forever – there’s no retroactive access. The same
is true when your ActivityPub server connects with a peer for the first time: you only ever get new content after that point. RSS, on the other hand, provides some number of “recent” items the moment you first subscribe.
Simple subscriptions. RSS can be served from a statically-hosted single file, which makes it suitable to
deploy anywhere as well as consume using anything. It can be read, after a fashion, in anything from Lynx upwards.
RSS ticks all these boxes. If I can choose between RSS and
ActivityPub to subscribe to your content, and I don’t need a real-time update, I’m probably going to choose RSS.
Obviously I appreciate that RSS and ActivityPub are different tools for different jobs, and there are doubtless
use-cases for which ActivityPub is clearly the superior solution.
I certainly don’t object to services providing both RSS and ActivityPub as syndication options, like
Mastodon does, where both might be good choices.
I use a tool called Sonarr to, uhh1, keep track of when new episodes of television
shows are released, regardless of what platform they’re on (Netflix, Prime, iPlayer, whatever) and notify me so I remember to watch it.
For several years, I’ve used IFTTT as the intermediary, receiving webhooks from Sonarr and
translating them for Slack:
This worked for years, but it’s time to retire it.
IFTTT‘s move to kill its Legacy Pro plan2 – which
I was on – gave me reason to re-assess this configuration. It turns that the only Pro feature I was using was an IFTTT “filter” to convert the Sonarr webhooks to a
Slack-friendly-format.
Given that I’m running an installation of Huginn on my home network anyway, I resolved to re-implement this flow in Huginn and
cancel my IFTTT subscription.
Raven-powered automation is the new hotness.
This turned out to be so easy I wonder why I never did it before.
First, I created a Webhook Agent and gave the URL to Sonarr.
Then I connected that to a Slack Agent with the following configuration:
I’ve omitted my Slack webhook URL so you don’t spam me. I tried for far too long to get the pluralize filter to
work so it’d say “episode” or “episodes” as appropriate before realising I didn’t care enough and gave up.
Then all I needed to do was re-emit some of the previous webhooks to test it:
As a bonus, I swapped out the IFTTT logo for Slackmoji’s :tv: icon and added the “Sonarr” username, as shown in my code sample.
Now I’ll continue to know when there’s new television to watch3!
I love the power and flexibility that Huginn provides to help automate your life. It does many of the things that I used to do with a handful of cron jobs and shell scripts, but all in
one convenient place.
Footnotes
1 I’ve heard there are other uses for the tool. Your mileage may vary. Don’t forget to pay
for your content, if possible.
3 It’s especially useful when you’re between seasons or a show is on hiatus to be reminded
that it’s back and I should go and watch it. Hey, there’s a thought: I wonder if I can extract the subtitles from shows and run them through a summarising LLM to give me a couple of paragraphs reminding me “what happened last series” if the show’s been on a long break?
During a family holiday last week to the Three Valleys region of the French Alps for some skiing1, I
came to see that I enjoy a privilege I call the freedom of the mountain.
“Mornin’. Let’s go skiing.”
The Freedom
The freedom of the mountain is a privilege that comes from having the level of experience necessary to take on virtually any run a resort has to offer. It provides a handful of
benefits denied to less-confident skiers:
I usually don’t feed to look at a map to plan my next route; whichever way I go will be fine!
When I reach one or more lifts, I can choose which to take based on the length of their queue, rather than considering their destinations.
When faced with a choice of pistes (or an off-piste route), my choice can be based on my mood, how crowded they are, etc., rather than their rated difficulty.
Let’s tear this up, yo.
The downside is that I’m less well-equipped to consider the needs of others! Out skiing with Ruth one morning I suggested a route back into town that “felt easy” based on my previous
runs, only to have her tell me that – according to the map – it probably wasn’t!
Approaching the Peak
The kids spent the week in lessons. It’s paying off: they’re both improving fast, and the eldest has got all the essentials down and it’s working on improving her parallel turns and on
“reading the mountain”. It’s absolutely possible that the eldest, and perhaps both of them, will be a better skier than me someday2.
I’m not perfect, mind. While skiing backwards and filming, I misjudged the height of an arch and hit the back of the head with it… despite the child shouting to warn me! 😅
Maybe, as part of my effort to do what I’m bad at, I should have another go at learning to
snowboard. I always found snowboarding frustrating because everything I needed to re-learn was something that I could already do much better and easier on skis. But perhaps if I can
reframe that frustration through the lens of learning itself as the destination, I might be in a better place. One to consider for next time I hit the piste.
Progressive enhancement is a great philosophy for Web application development. Deliver all the essential basic functionality using the simplest standards available; use advanced
technologies to add bonus value and convenience features for users whose platform supports them. Win.
JavaScript disabled/enabled is one of the most-fundamental ways to differentiate a basic from an enhanced experience, but it’s absolutely not the only way (especially now that feature
detection in JavaScript and in CSS has become so powerful!).
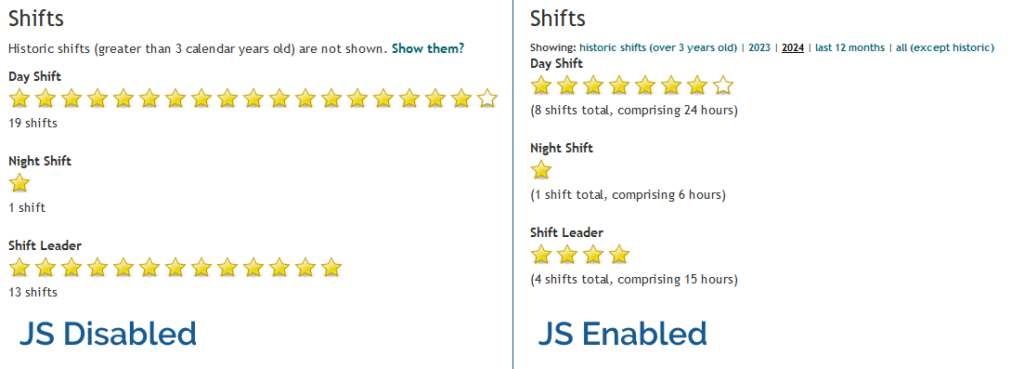
In Three Rings, for example, volunteers can see a “starchart” of the volunteering shifts they’ve done recently, at-a-glance, on
their profile page1.
In the most basic case, this is usable in its HTML-only form: even with no JavaScript, no CSS, no images even, it still functions. But if JavaScript is enabled, the volunteer can dynamically “filter” the year(s) of volunteering
they’re viewing. Basic progressive enhancement.
If a feature requires JavaScript, my usual approach is to use JavaScript to add the relevant user interface to the page in the first place. Those starchart filters in Three
Rings don’t appear at all if JavaScript is disabled. A downside to this approach is that the JavaScript necessarily modifies the DOM on page load, which introduces a delay to the page being interactive as well as potentially resulting in layout shift.
That’s not always the best approach. I was reminded of this today by the website of 7-year-old Shiro (produced with, one assumes, at least
a little help from Saneef H. Ansari). Take a look at this progressively-enhanced theme switcher:
No layout shift, no
DOM manipulation. And yet it’s still pretty clear what features are available.
The HTML that’s delivered over-the-wire provides a disabled<select> element, which gains the CSS directive cursor: not-allowed;, to make it clear to the used that this dropdown doesn’t do anything. The whole thing’s wrapped
in a custom element.
When that custom element is defined by the JavaScript, it enhances the dropdown with an event listener that implements the theme changes, then enables the disabled
<select>.
I’m not convinced by the necessity of the <form> if there’s no HTML-only fallback… and the <label>
probably should use a for="..." rather than wrapping the <select>, but otherwise this code is absolutely gorgeous.
It’s probably no inconvenience to the minority of JS-less users to see a theme switcher than, when they go to use it, turns out to be
disabled. But it saves time for virtually everybody not to have to wait for JavaScript to manipulate the DOM, or else to risk
shifting the layout by revealing a previously-hidden element.
Altogether, this is a really clever approach, and I was pleased today to be reminded – by a 7-year-old! – of the elegance of this approach. Nice one Shiro (and Saneef!).
Footnotes
1 Assuming that administrators at the organisation where they volunteer enable this
feature for them, of course: Three Rings‘ permission model is robust and highly-customisable. Okay, that’s enough sales pitch.
I guess I’ve always been more of a sprinter/hurdles blogger than a marathon runner.
Might I meet that challenge? Maybe. But it turns out it’s easier than I thought because Kev revised the rules to require only 100 posts in a calendar year (or any other 365-day period, but I’m not
going to start thinking about the maths of that).
That’s not only much more-achievable… I’ve probably already achieved it! Let’s knock out some SQL to check how many posts I
made each year:
SELECTYEAR(wp_posts.post_date_gmt) yyyy,
COUNT(wp_posts.ID) total
FROM
wp_posts
WHERE
wp_posts.post_status='publish'AND wp_posts.post_type='post'GROUPBY yyyy
ORDERBY yyyy
My code’s actually a little more-complicated than this, because of some plot, but this covers the essentials.
A big question in some years is what counts as a post. Kev’s definition is quite liberal and includes basically-everything, but I wonder if mine shouldn’t perhaps be stricter.
For example:
Should I count checkins, even though they’re not always born as blog posts but often start as logs on geocaching websites?
(My gut says yes!)
Do reposts and bookmarks contribute, a significant minority of which are presented without any further
interpretation by me? (My gut says no!)
Does a vlog version of a blog post count separately, or is it a continuation of the same content? (My gut says the volume is too
low to matter!)
Can a retroactive achievement (i.e. from before the challenge was announced) count? Kev writes “there is no specific start date”, but it seems a little counter to
the idea of it specifically being a challenge to claim it when you weren’t attempting the challenge at the time.
Some posts are lost from 1998/1999. If they were recovered I might have made 100 posts in 1999, but probably not in 1998 as I only started blogging on 27 September 1998.
A heartfelt post about saying goodbye to Aberystwyth as I moved to Oxford on 16 June was my 100th of the year. Pedants might argue that
this year shouldn't count, but so long as you're willing to count checkins (and you should) then it would... and my qualifying post would have come only a couple of days
later, with a post about the Headington Shark, which I had just moved-in near to.
I'm not convined this low-blogging year should count: a clear majority of the posts were geocaching logs, and they weren't always even that verbose (consider this candidate for 100th post of 2013, from 1 October).
Another geocache log heavy, conventional blogpost light year that I'm not convinced should count, evem if the obvious candidate for 100th post would be 18 May's cool article about
geocaching like Batman!
I maintain that checkins should count, even when they're PESOS'd from geocaching sites, so long as they don't make up a majority of the qualifying posts in a year. In
which case this year should qualify, with the 100th post being my visit to this well-hidden London pub
while on my way to a conference.
My blogging ramped up again this year, and on 24 August I shared a motivational poster with a funny twist, plus a pun at the intersection
between my sexuality and my preferred mode of transport.
Total count of all the posts.
Doesn't add up? Not all posts feature in one of the years above!
* Pedants might claim this year was not a success for the reasons described above. Make your own mind up.
In any case, I’d argue that I clearly achieved the revised version of the challenge on certainly six, probably fourteen, arguably (depending on how you count posts) as
many as nineteen different years since I started blogging in 1998. My least-controversial claims would be:
Given all these unanswered questions, I’m not going to just go ahead and raise a PR against the Hall of Fame! Instead, I’ll leave it to
Kev to decide whether I’m (a) eligible to claim a 14-time award, (b) merely eligible for a 4-time award for the years following the challenge starting, or (c) ineligible to claim
success until I intentionally post 100 times in a year (in, at current rates, another two months…). Over to you, Kev…
Update: Kev’s agreed that I can claim the most-recent four of them, so I raised a PR.


























{kind=link}